交易Agent为何表面聪明,实际却常显半成品;多Agent架构如何带来转机。
在金融AI领域,许多交易Agent项目乍看之下令人印象深刻。它们能够快速处理股票代码、时间范围以及相关参数,输出看似专业的分析报告,甚至直接给出买入或卖出的建议。这种演示效果往往吸引眼球,让人觉得AI已经接近或超越人类交易员的水平。然而,当真正尝试将其作为可靠的研究或决策工具时,问题便逐渐浮出水面。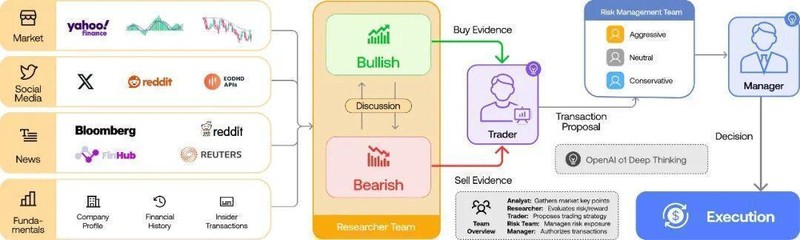
这些系统通常只呈现最终结论,却缺少完整的推理过程。它们给出判断,但鲜有内部观点冲突;它们输出结果,却没有机制来质疑、验证或平衡这些结果。这种单一路径的决策方式,导致用户在使用时总有一种不踏实的感觉,仿佛系统虽流畅,却缺少真实交易环境中那种多方博弈的深度与稳健。究其原因,并非模型本身能力不足,而是整体组织结构设计过于简单扁平,角色分工不够细致,制衡机制严重缺失。
真实交易团队的成功,很大程度上依赖于明确的分工与协作。分析师关注财务数据与基本面,研究员挖掘新闻与市场情绪,技术专家解读图表与指标,风控人员严格把控风险敞口,而组合经理则统筹全局仓位。这种多角色协作并非多余,而是金融决策复杂性的必然要求。缺少任何一方,都可能导致判断偏差或风险失控。因此,单纯依靠单一Agent或浅层多Agent链路的系统,自然难以复刻出专业水准的交易流程。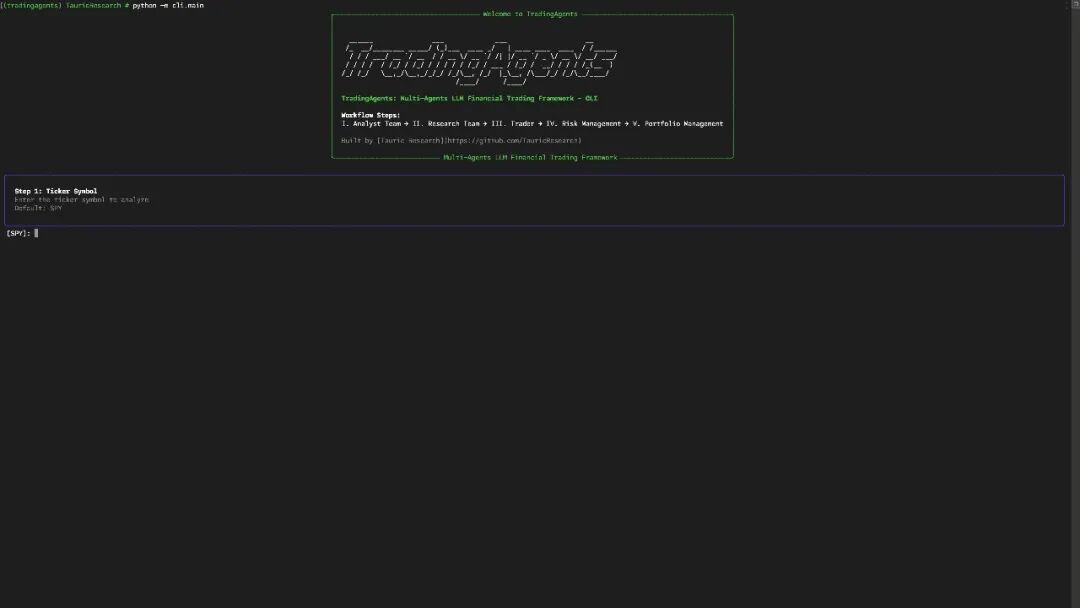
TradingAgents项目正是在这一痛点上提供了富有启发的解决方案。该框架由UCLA与MIT研究者合作开发,从一开始就定位于构建多智能体金融交易体系。它将交易过程拆解为多个专业团队:分析师团队覆盖基本面、情绪面、技术面等不同维度;研究员团队则分为看多与看空两派,进行深度辩论;随后由交易员、风险管理与组合经理负责执行审核与最终决策。这种结构不仅增加了角色数量,更关键的是引入了分歧与制衡机制,让系统内部能够自然产生反对声音与风险把关。
在实际运行中,这种辩论式协作显得尤为宝贵。金融市场充满不确定性,单一视角容易陷入乐观或悲观偏差,而允许Bullish与Bearish研究员公开对峙,则能更全面暴露潜在风险。系统不会急于给出统一结论,而是通过多轮讨论逐步逼近更可靠的判断。这种接近真实团队的决策路径,往往比快速输出的答案更有长期价值。它让用户看到结论背后的思考碰撞,也让整个过程更具可解释性与可信度。
此外,TradingAgents在工程实现上也展现出持续迭代的诚意。从论文初稿到后续版本更新,它已支持多家LLM提供商、CLI交互、Python包安装以及基于LangGraph的可扩展架构。这意味着用户不仅能体验概念验证,还能实际运行、调整参数、替换模型,甚至扩展新角色。这种从研究原型向实用框架的演进,标志着多Agent交易系统正逐步迈向成熟阶段。
回顾整个领域的发展轨迹,过去人们往往聚焦于数据规模、模型强度或推理链长度,但TradingAgents提醒从业者:真正高价值的金融AI系统,其核心竞争力在于能否模拟出协作组织的智慧。一个能容纳冲突、辩论与否决的框架,通常比单纯追求速度与统一性的系统更接近专业本质。它不只是技术创新,更是方法论上的深刻反思。
对于关注金融AI、多Agent体系或专业决策工具的开发者与研究者而言,这个项目值得深入拆解。它探讨的并非模型能否独立完成交易,而是整个交易研究流程能否通过合理的Agent组织结构得到更真实、更可靠的复现。这种视角转变,或许将成为未来金融Agent发展的关键方向。
项目开源地址位于GitHub相应仓库,欢迎感兴趣的朋友亲自体验与验证其多Agent协作的实际表现。